
Excelの「104万行の壁」を知っているか
皆さんは、Excelの最終行を見たことがあるでしょうか。 Ctrl + 矢印キー(下)を押したときに到達する、あの最果ての地です。 「1,048,576行」。 これが、Excelという表計算ソフトが許容するデータの限界値です。これを超えたデータは、警告とともに無慈悲に切り捨てられます。
しかし、現場の現実はもっとシビアです。 理論上の限界に達するずっと前、数万行を超えたあたりで、VLOOKUPの計算は遅くなり、オートフィルタをかけるだけで砂時計が回り続けます。 画面上部に表示される「応答なし」の白いモヤ。あれを見つめている時間は、人生において最も不毛な時間の一つと言えるでしょう。
データ量が多すぎるからと、CSVファイルを月別に分割して作業していませんか。 それは、あなたが本来やるべき仕事ではありません。
Snowflakeには、そのような行数制限はありません。 100万行も、1億行も、このプラットフォームにとっては誤差の範囲です。 今日、あなたのデスクトップにあるその「重たくて開けないCSV」を、一瞬で処理可能な状態にする手順をお伝えします。 道具を変えれば、景色は変わります。
データロードは「入国審査」である
Snowflakeを使い始めたばかりの方が、最初につまずく概念があります。 「ステージ(Stage)」と「ファイルフォーマット(File Format)」です。
Excelであれば、CSVファイルをダブルクリックすれば開きます。 しかし、Snowflakeのようなデータウェアハウスは、もう少し厳格な作法を求めます。 これを、海外旅行の「入国審査」に例えてみましょう。
PCにあるデータ(あなたの自宅)から、テーブル(入国後の滞在先)へ、いきなり荷物を投げ込むことはできません。 一度、「ステージ」と呼ばれる場所(空港の税関)に荷物を置く必要があります。 そこで、「ファイルフォーマット」というパスポートの提示を求められます。 「この荷物はCSV形式か、JSONか」 「区切り文字はカンマか」 「文字コードはUTF-8か、それともShift-JISか」。
この確認プロセスを経て初めて、データはテーブルの中に格納されます。 一見、面倒な手続きに見えるかもしれません。 しかし、建築において基礎工事を疎かにすれば建物が傾くように、データの入り口で厳格なチェックを行うからこそ、中に入ったデータは「信頼できる情報」として扱えるのです。 汚いデータをそのまま流し込まない。これは、堅牢なデータ基盤を作るための必要な儀式なのです。
実践:GUIならドラッグ&ドロップで終わる
ではまずメニューを日本語にしましょう!
1.左下のプロフィールアイコンをクリック
画面左端のメニュー最下部にある、ご自身のユーザー名(またはイニシャル)が表示されているアイコンをクリックし、「設定」をクリックします。
2.「Profile」を選択
表示されたメニューの中から Profile をクリックしてください。
3.Language(言語)の設定を探す
プロフィール設定画面が開きます。その中の Language という項目を探してください。
4.「Japanese (日本語)」を選択して保存
ドロップダウンメニューから Japanese (日本語) を選択します。
設定を変更すると、画面が自動的にリロード(再読み込み)され、メニューが日本語に切り替わります。
これでメニューも日本語になりましたね。では次に進みます。
まず、データを運ぶには、トラックのエンジンをかける必要があります。Snowflakeではこれを「ウェアハウス(Warehouse)」と呼びます。 難しいことはありません。管理画面の「Manage」メニューから「コンピュート(Compute)」をクリックすると[ウェアハウスWarehouse]というタブがでてきます。

ウェアハウスが3つならんでいます。これはSnowflakeが最初から親切に用意してくれたものと自動で作られたものです。今回はCOMPUTE_WHを使います。
概念を理解したところで、実際にデータを投入してみましょう。 現代のSnowflakeには、直感的に操作できる管理画面「Snowsight」があり、優秀なウィザードが用意されています。
1. データベースとスキーマを作る(データの住所を決める)
まずはデータを格納するための「箱」を用意します。
左メニューの中ほどにある [Horizon Catalog] グループをクリックし、続けて [カタログ] を選択します。
画面右上の青い [+ データベース] ボタンを押し、名前に TEST_DB と入力して「作成」をクリックします。
作成された TEST_DB が一覧に出るので、その名前をクリックして中に入ります。
次に [+ スキーマ] ボタンを押し、名前に TEST_SCHEMA と入力して「作成」をクリックします。
2. 「ロード」ウィザードを起動する
作成した TEST_SCHEMA の中に入ると、まだテーブル(表)が一つもない状態です。ここからデータの「入国審査」を開始します。
画面右上にある青い [作成] ボタンをクリックします。
メニューから [テーブル] → [ファイルから] を選択してください。これが魔法の入り口です。
3. CSVをドラッグ&ドロップする
「テーブルへのデータのロード」という画面が立ち上がります。
手元のCSVファイルを、画面中央の点枠の中にドラッグ&ドロップします。
アップロードが完了するとファイル名が表示されるので、画像下部の 「名前」 と書かれたすぐ下の空の入力欄に、作成したいテーブルの名前(例:TEST_TABLE など)を入力してください。右下の [次へ] をクリックします。
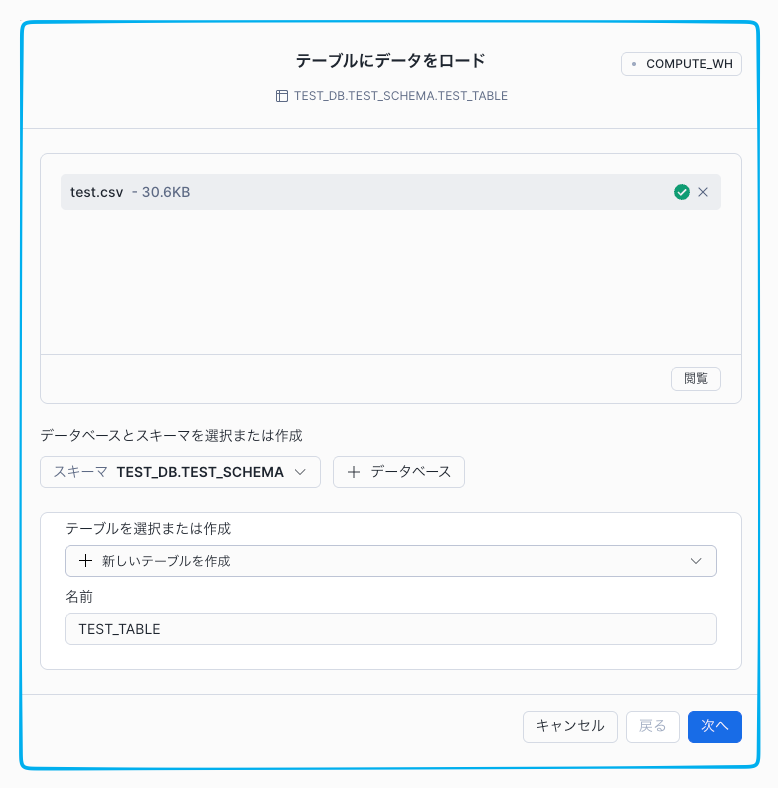
4.プレビューとファイル形式(入国審査の最終確認)
ここが最も重要な「検疫」のステップです。Snowflakeがデータの中身を自動で解析し、どのように取り込むべきかを提案してくれます。
・ファイル形式の確認(左側パネル): 画面左上の「ファイル形式」で「Delimited Files (CSV or TSV)」が選択されていることを確認します。
・「オプションを表示」が鍵: もし右側のプレビューが1列に固まっていたり、文字化けしていたりする場合は、左側にある青い文字の「オプションを表示」をクリックしてください。
・文字化け・見出しの対応: 「オプションを表示」を押すと出てくる詳細設定で、以下の2点を調整します。
・文字コード: 「エンコーディング」を、元のファイルに合わせて「UTF-8」や「Shift-JIS」に切り替えます。
・ヘッダー(見出し): 「ヘッダーを含む最初の行」という設定項目を確認します。これにチェックを入れることで、CSVの1行目を見出しとして正しく認識させることができます。
・列の定義(右側パネル): 画面右側には、Snowflakeが推測した「列名」と「データ型(文字列や数値など)」が並んでいます。
現在は「c1」「c2」のように仮の名前が付いていますが、ここを直接クリックして「日付」「金額」のように分かりやすい名前に書き換えることも可能です。
5.実行
プレビューの内容がExcelのように綺麗に整い、各データが適切な列に収まっていることを確認したら、準備完了です。右下の青い [ロード] ボタンをクリックしましょう。
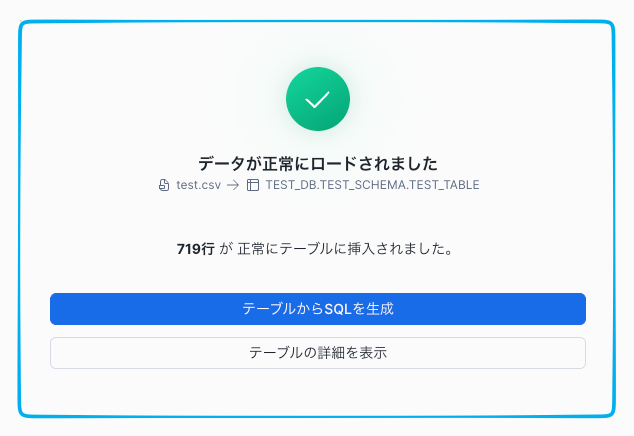
これでロードが完了、テストデータの719行のデータが無事に TEST_DB.TEST_SCHEMA.TEST_TABLE へ格納されました。
このGUIを使った操作手順については、前回ご紹介した書籍『ゼロからのデータ基盤 Snowflake実践ガイド』でも丁寧に解説されています。手元に置いておくと、迷った時の羅針盤になるでしょう。
書籍:ゼロからのデータ基盤 Snowflake実践ガイド ※Kindle版もありますが、図解を確認しながら操作するには紙の本が便利です。
Udemy:Snowflakeの基礎を学ぶ講座 ハンズオン形式で手を動かしながら学びたい方には、動画講座も有効な選択肢です。
検証:100万行を一瞬で数える快感
ロードが完了し、緑のチェックマークが表示されたら、いよいよ「放流」の成果を確認しましょう。 これまでの苦労が報われる瞬間です。
1. ワークシートを起動する
ロード完了画面にある [テーブルからSQLを生成] ボタンをクリックしてください。 自動的に「ワークシート」という、SQLを記述・実行するためのエディタが立ち上がります。
2. 全行数を数える(COUNT)
エディタにはすでにSQLが入力されているかもしれませんが、まずはシンプルに件数を確認してみましょう。 以下の1行を入力(または書き換え)してみてください。
SELECT COUNT(*) FROM TEST_TABLE;
画面右上の [Run] (再生ボタン) をクリックするか、Command (Ctrl) + Enter を叩いてください。 さきほどあなたがロードしたデータ件数が一瞬で表示されます。
3. データの顔ぶれを見る(SELECT *)
次に、中身を10行だけ覗いてみましょう。
SELECT * FROM TEST_TABLE LIMIT 10;
Excelならスクロールするたびにフリーズしていたあのデータが、今はあなたの指先一つで自在に動いています。
待つ必要はありません。ストレスもありません。 この「データを完全に掌握している」という全能感こそが、データエンジニアとしての第一歩であり、最大の醍醐味です!
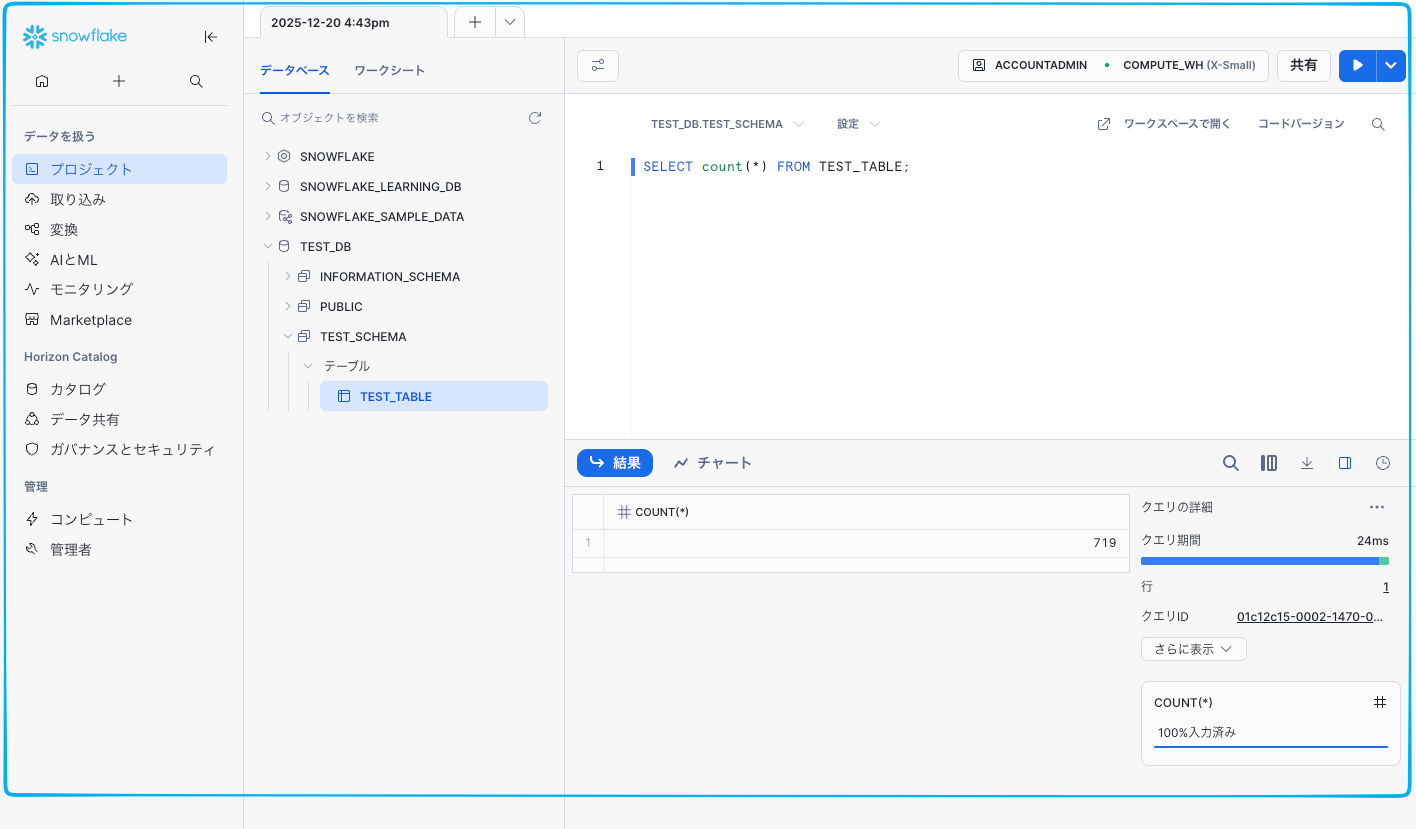
なお、一旦この画面を閉じたあとや別のメニューに移動した後に、SQLを実行する画面(ワークシート)に戻る手順は以下の通りです。
・左メニューの [プロジェクト] をクリック 左端のメニューの一番上にある、フォルダのようなアイコンのメニューです。
・[ワークシート] を選択 [プロジェクト] をクリックすると展開されるメニューの中から [ワークシート] をクリックします。
・作成済みのワークシートを選ぶ 画面中央に、これまでに作成したワークシートの一覧が表示されます。
先ほど「テーブルからSQLを生成」で自動作成されたものも、ここに保存されています。
新しく作りたい場合は、右上の [+ ワークシート] ボタン(または [+] アイコン)から [SQLワークシート] を選んでください。
次回予告:VLOOKUPの葬送
データは無事にSnowflakeという湖に放流されました。 しかし、現時点ではまだ「生の素材」が入っただけです。 業務で使うためには、ここから加工し、集計する必要があります。
Excel職人の皆さんなら、ここで「VLOOKUP関数」を使って別のシートと突き合わせる作業を想像するでしょう。 そして、その計算処理の重さに再び絶望するかもしれません。
安心してください。Snowflakeの世界にVLOOKUPによる待ち時間はありません。 次回は、Excel職人の必殺技であるVLOOKUPを、SQLの「JOIN(結合)」に置き換える方法を解説します。 複数のCSVを結合し、集計し、レポートを作る。Excelで3時間かかっていた作業を、3秒にする魔法をお教えしましょう。
その苦労は、仕組みで解決できます。一緒に構造をほどいていきましょう!